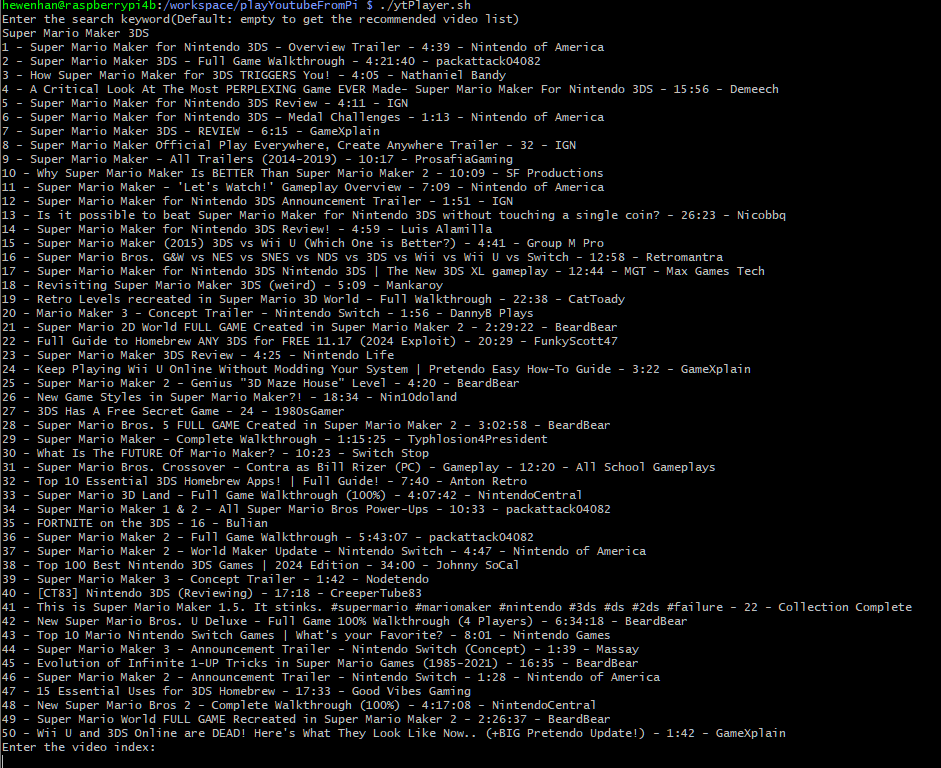
Docker 构建 SD 1.5 webui
Blind Holmes
v0.0.1
Written with StackEdit.
搭建流程记录
下载 nvidia 官方 cuda 镜像
https://hub.docker.com/r/nvidia/cuda/tags
docker pull nvidia/cuda:12.2.0-devel-ubuntu20.04
运行并创建容器
docker run -id --name sd nvidia/cuda:12.2.0-devel-ubuntu20.04 /bin/bash
连接容器
docker exec -it sd /bin/bash
安装必要环境
apt update; apt install wget git python3 python3-venv python3-pip sudo libgoogle-perftools4 libtcmalloc-minimal4 vim net-tools
创建用户
adduser user
adduser user sudo
以新用户连接容器
docker exec -it --user 1000 sd /bin/bash
创建 SD 目录
sudo mkdir /opt/stable_diffusion_webui;
sudo chown user:user /opt/stable_diffusion_webui;
安装 SD_WEB_UI
遵循:https://github.com/AUTOMATIC1111/stable-diffusion-webui
cd /opt/stable_diffusion_webui;
bash <(wget -qO- https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh);
执行后遇到错误
RuntimeError: Torch is not able to use GPU; add --skip-torch-cuda-test to COMMANDLINE_ARGS variable to disable this check
于是直接执行 py 脚本
python3 launch.py
安装了一些依赖以后还是遇到错误
RuntimeError: Torch is not able to use GPU; add --skip-torch-cuda-test to COMMANDLINE_ARGS variable to disable this check
根据提示,增加参数执行
python3 launch.py --skip-torch-cuda-test
之后继续下载并安装必要依赖
猜测错误来源:我是使用的 AMD R9 7945HX + RTX 4070 的笔记本,核显 + 独显的组合,虽然开了独显直连模式,但是在显卡识别上面可能还是有问题,比如识别到了 AMD 集显所以在 cuda 测试中出错。暂时不确定是否是 Torch 的问题。
运行一段时间之后又有报错
ImportError: libGL.so.1: cannot open shared object file: No such file or directory
尝试安装系统依赖:
sudo apt install ffmpeg libsm6 libxext6
安装过程中涉及到 tzdata 的时区设定……需要手动设定,这里是个问题!
设置为非交互式安装可以搞定
DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends tzdata
之后继续执行 launch.py,继续正常下载安装……
之后再度遭遇报错
RuntimeError: "addmm_impl_cpu_" not implemented for 'Half'
RuntimeError: "LayerNormKernelImpl" not implemented for 'Half'
貌似还是显卡识别的问题,先尝试增加执行参数,另外再增加本地端口监听等,方便外部访问
python3 launch.py --skip-torch-cuda-test --precision full --no-half --listen --enable-insecure-extension-access --theme dark --gradio-queue
终于运行起来了,并且能够从外部访问并安装扩展。出图会调用 CPU,速度奇慢无比。接下来要解决一下 CUDA 调用问题……
试试添加参数 --xformers 运行
python3 launch.py --skip-torch-cuda-test --precision full --no-half --listen --enable-insecure-extension-access --theme dark --gradio-queue --xformers
失败,还是 CPU 在执行,并且出图报错:
NotImplementedError: No operator found for `memory_efficient_attention_forward` with inputs: query : shape=(1, 4096, 1, 512) (torch.float32) key : shape=(1, 4096, 1, 512) (torch.float32) value : shape=(1, 4096, 1, 512) (torch.float32) attn_bias : <class 'NoneType'> p : 0.0 `cutlassF` is not supported because: device=cpu (supported: {'cuda'}) `flshattF` is not supported because: device=cpu (supported: {'cuda'}) dtype=torch.float32 (supported: {torch.float16, torch.bfloat16}) max(query.shape[-1] != value.shape[-1]) > 128 `tritonflashattF` is not supported because: device=cpu (supported: {'cuda'}) dtype=torch.float32 (supported: {torch.float16, torch.bfloat16}) max(query.shape[-1] != value.shape[-1]) > 128 Operator wasn't built - see `python -m xformers.info` for more info triton is not available `smallkF` is not supported because: max(query.shape[-1] != value.shape[-1]) > 32 unsupported embed per head: 512
Time taken: 1m 1.21s
估计还是 cuda 调用方面各种问题,看来需要解决一下看看能不能把 --skip-torch-cuda-test --precision full --no-half 这种参数去掉
我在容器内创建一个脚本 test.py
#!/usr/bin/env python3
# coding=utf-8
import torch
print(torch.cuda.device_count()) # --> 0
print(torch.cuda.is_available()) # --> False
print(torch.version.cuda) # --> 9.0.176
print(torch.cuda.current_device())
print(torch.cuda.is_available())
执行后,打印
/home/user/.local/lib/python3.8/site-packages/torch/cuda/__init__.py:546: UserWarning: Can't initialize NVML
warnings.warn("Can't initialize NVML")
0
False
11.8
Traceback (most recent call last):
File "./test.py", line 10, in <module>
print(torch.cuda.current_device())
File "/home/user/.local/lib/python3.8/site-packages/torch/cuda/__init__.py", line 674, in current_device
_lazy_init()
File "/home/user/.local/lib/python3.8/site-packages/torch/cuda/__init__.py", line 247, in _lazy_init
torch._C._cuda_init()
RuntimeError: No CUDA GPUs are available
可以看出来,完全无法调用 cuda 啊啊。
于是退出 docker,在本机环境安装 torch 后创建并执行同一脚本,打印:
1
True
11.7
0
True
看来,我本机 cuda 驱动和依赖应该没这个问题,那么就还是 docker image 的原生环境问题。
思考一下,找找其他解决方案。
找到了这个:
https://stackoverflow.com/questions/54264338/why-does-pytorch-not-find-my-nvdia-drivers-for-cuda-support
从
https://catalog.ngc.nvidia.com/orgs/nvidia/containers/pytorch/tags
中拉取现成的 nv pytorch 镜像,编写一个简单的 docker compose 脚本就可以了
看来 nv 专门针对这种场景搞了 docker 镜像,前面是走了弯路了……
使用说明:
https://catalog.ngc.nvidia.com/orgs/nvidia/containers/pytorch
唉……,要从头开始了……
docker pull nvcr.io/nvidia/pytorch:23.06-py3
镜像有 8.58 GB,下载过程中正好来整理一下前面的安装命令
安装系统环境
apt update && \
apt upgrade -y && \
DEBIAN_FRONTEND=noninteractive \
apt install -y --no-install-recommends \
wget git python3 python3-venv python3-pip sudo libgoogle-perftools4 libtcmalloc-minimal4 ffmpeg libsm6 libxext6 libpng-dev libjpeg-dev vim net-tools && \
adduser --disabled-password --gecos '' user && \
echo -e "000000\n000000" | passwd user && \
adduser user sudo && \
mkdir /opt/sd && \
chown user:user /opt/sd && \
runuser -l user -c 'cd /opt/sd && bash <(wget -qO- https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh)'
梳理差不多了,镜像也下载完
先把之前的容器改个名字
docker rename sd sd_bak
然后生成新的容器
docker run --gpus all -id --name sd nvcr.io/nvidia/pytorch:23.06-py3
结果上来就报错哈哈
docker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]].
查了一下本机要先安装 nvidia-container-toolkit
https://github.com/NVIDIA/nvidia-container-toolkit
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
https://www.server-world.info/en/note?os=Ubuntu_22.04&p=nvidia&f=2
注意系统版本,使用本机 root 用户执行命令:
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | apt-key add -;
curl -s -L https://nvidia.github.io/nvidia-docker/ubuntu22.04/nvidia-docker.list > /etc/apt/sources.list.d/nvidia-docker.list;
apt install -y nvidia-container-toolkit;
service docker restart;
接下来执行容器化
docker run --gpus all -id --name sd nvcr.io/nvidia/pytorch:23.06-py3
成功!啥也不说,先确认一下 torch 的情况,登入容器
docker exec -it sd /bin/bash
直接命令行检查
root@a26289624dd6:/workspace# python
Python 3.10.6 (main, May 29 2023, 11:10:38) [GCC 11.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> print(torch.cuda.device_count())
1
>>> print(torch.cuda.is_available())
True
>>> print(torch.version.cuda)
12.1
>>> print(torch.cuda.current_device())
0
>>> print(torch.cuda.is_available())
True
>>>
赞!有了!直接执行整理好的命令集,直接成了
执行命令运行环境
python3 launch.py --listen --enable-insecure-extension-access --theme dark --gradio-queue --xformers
倒是可以运行起来了,但是这里出了一个插曲,xformers 报错:
Launching Web UI with arguments: --listen --enable-insecure-extension-access --theme dark --gradio-queue --xformers
NOTE! Installing ujson may make loading annotations faster.
WARNING[XFORMERS]: xFormers can't load C++/CUDA extensions. xFormers was built for:
PyTorch 2.0.1+cu118 with CUDA 1108 (you have 2.1.0a0+4136153)
Python 3.10.11 (you have 3.10.6)
Please reinstall xformers (see https://github.com/facebookresearch/xformers#installing-xformers)
Memory-efficient attention, SwiGLU, sparse and more won't be available.
Set XFORMERS_MORE_DETAILS=1 for more details
*** Error setting up CodeFormer
Traceback (most recent call last):
File "/opt/sd/stable-diffusion-webui/modules/codeformer_model.py", line 33, in setup_model
from facelib.utils.face_restoration_helper import FaceRestoreHelper
File "/opt/sd/stable-diffusion-webui/repositories/CodeFormer/facelib/utils/face_restoration_helper.py", line 7, in <module>
from facelib.detection import init_detection_model
File "/opt/sd/stable-diffusion-webui/repositories/CodeFormer/facelib/detection/__init__.py", line 11, in <module>
from .yolov5face.face_detector import YoloDetector
File "/opt/sd/stable-diffusion-webui/repositories/CodeFormer/facelib/detection/yolov5face/face_detector.py", line 20, in <module>
IS_HIGH_VERSION = tuple(map(int, torch.__version__.split('+')[0].split('.'))) >= (1, 9, 0)
ValueError: invalid literal for int() with base 10: '0a0'
---
可能在依赖安装顺序上存在问题,于是重新安装 pip 依赖试试看
/usr/bin/python3 -m pip install --upgrade pip;
pip install torch==2.0.0+cu118 torchvision==0.15.1+cu118 torchaudio==2.0.1+cu118 torchtext==0.15.1 torchdata==0.6.0 --extra-index-url https://download.pytorch.org/whl/cu118 -U;
pip install xformers==0.0.19 triton==2.0.0 -U
呃,装完依赖以后项目直接跑不起来了
Launching Web UI with arguments: --listen --enable-insecure-extension-access --theme dark --gradio-queue --xformers
/home/user/.local/lib/python3.10/site-packages/torchvision/io/image.py:13: UserWarning: Failed to load image Python extension: '/home/user/.local/lib/python3.10/site-packages/torchvision/image.so: undefined symbol: _ZN3c106detail23torchInternalAssertFailEPKcS2_jS2_RKSs'If you don't plan on using image functionality from `torchvision.io`, you can ignore this warning. Otherwise, there might be something wrong with your environment. Did you have `libjpeg` or `libpng` installed before building `torchvision` from source?
warn(
Traceback (most recent call last):
File "/opt/sd/stable-diffusion-webui/launch.py", line 38, in <module>
main()
File "/opt/sd/stable-diffusion-webui/launch.py", line 34, in main
start()
File "/opt/sd/stable-diffusion-webui/modules/launch_utils.py", line 340, in start
import webui
File "/opt/sd/stable-diffusion-webui/webui.py", line 28, in <module>
import pytorch_lightning # noqa: F401 # pytorch_lightning should be imported after torch, but it re-enables warnings on import so import once to disable them
File "/home/user/.local/lib/python3.10/site-packages/pytorch_lightning/__init__.py", line 35, in <module>
from pytorch_lightning.callbacks import Callback # noqa: E402
File "/home/user/.local/lib/python3.10/site-packages/pytorch_lightning/callbacks/__init__.py", line 14, in <module>
from pytorch_lightning.callbacks.batch_size_finder import BatchSizeFinder
File "/home/user/.local/lib/python3.10/site-packages/pytorch_lightning/callbacks/batch_size_finder.py", line 24, in <module>
from pytorch_lightning.callbacks.callback import Callback
File "/home/user/.local/lib/python3.10/site-packages/pytorch_lightning/callbacks/callback.py", line 25, in <module>
from pytorch_lightning.utilities.types import STEP_OUTPUT
File "/home/user/.local/lib/python3.10/site-packages/pytorch_lightning/utilities/types.py", line 27, in <module>
from torchmetrics import Metric
File "/home/user/.local/lib/python3.10/site-packages/torchmetrics/__init__.py", line 14, in <module>
from torchmetrics import functional # noqa: E402
File "/home/user/.local/lib/python3.10/site-packages/torchmetrics/functional/__init__.py", line 14, in <module>
from torchmetrics.functional.audio._deprecated import _permutation_invariant_training as permutation_invariant_training
File "/home/user/.local/lib/python3.10/site-packages/torchmetrics/functional/audio/__init__.py", line 14, in <module>
from torchmetrics.functional.audio.pit import permutation_invariant_training, pit_permutate
File "/home/user/.local/lib/python3.10/site-packages/torchmetrics/functional/audio/pit.py", line 23, in <module>
from torchmetrics.utilities import rank_zero_warn
File "/home/user/.local/lib/python3.10/site-packages/torchmetrics/utilities/__init__.py", line 14, in <module>
from torchmetrics.utilities.checks import check_forward_full_state_property
File "/home/user/.local/lib/python3.10/site-packages/torchmetrics/utilities/checks.py", line 25, in <module>
from torchmetrics.metric import Metric
File "/home/user/.local/lib/python3.10/site-packages/torchmetrics/metric.py", line 30, in <module>
from torchmetrics.utilities.data import (
File "/home/user/.local/lib/python3.10/site-packages/torchmetrics/utilities/data.py", line 22, in <module>
from torchmetrics.utilities.imports import _TORCH_GREATER_EQUAL_1_12, _XLA_AVAILABLE
File "/home/user/.local/lib/python3.10/site-packages/torchmetrics/utilities/imports.py", line 48, in <module>
_TORCHAUDIO_GREATER_EQUAL_0_10: Optional[bool] = compare_version("torchaudio", operator.ge, "0.10.0")
File "/home/user/.local/lib/python3.10/site-packages/lightning_utilities/core/imports.py", line 73, in compare_version
pkg = importlib.import_module(package)
File "/usr/lib/python3.10/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "/home/user/.local/lib/python3.10/site-packages/torchaudio/__init__.py", line 1, in <module>
from torchaudio import ( # noqa: F401
File "/home/user/.local/lib/python3.10/site-packages/torchaudio/_extension/__init__.py", line 43, in <module>
_load_lib("libtorchaudio")
File "/home/user/.local/lib/python3.10/site-packages/torchaudio/_extension/utils.py", line 61, in _load_lib
torch.ops.load_library(path)
File "/home/user/.local/lib/python3.10/site-packages/torch/_ops.py", line 643, in load_library
ctypes.CDLL(path)
File "/usr/lib/python3.10/ctypes/__init__.py", line 374, in __init__
self._handle = _dlopen(self._name, mode)
OSError: libcudart.so.11.0: cannot open shared object file: No such file or directory
删掉项目目录中的 venv 目录,重新执行 webui.sh
经过一轮安装后问题照旧,经过调试,发现其实是 torchvision 无法被引入导致,那么激活 venv 重装 torchvision 试试,重装还报错了
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
xformers 0.0.20 requires pyre-extensions==0.0.29, which is not installed.
numba 0.57.1 requires numpy<1.25,>=1.21, but you have numpy 1.25.1 which is incompatible.
google-auth 2.22.0 requires urllib3<2.0, but you have urllib3 2.0.3 which is incompatible.
blendmodes 2022 requires Pillow<10,>=9.0.0, but you have pillow 10.0.0 which is incompatible.
不过项目倒是 run 起来了,现在遇到了显存分配问题
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 7.73 GiB total capacity; 3.42 GiB already allocated; 42.25 MiB free; 3.47 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
查了一些资料,怀疑是进程通讯限制导致的,增加 --ipc host 参数,再重来了
docker run --gpus all --ipc host -id --name sd nvcr.io/nvidia/pytorch:23.06-py3
还是不行,经历了若干轮重装后,各种报错,总之,最后要重装 xformers
pip3 install -U xformers
奇怪,装完了以后 venv 消失了……
又经过重装,回到原点,重装 torchvision 试试
pip install --force-reinstall torchvision
成了!终于正常 run 起来!测试了一下出图,查看运行效率和 cpu 占用,都正常。终于搞定了。
整个安装流程需要好好梳理一下!